import requests,re
p=input('请输入页面地址:')
e=0
for o in range(1,4):
url=f'https://www.1ppt.com/moban/{p}/ppt_{p}_{o}.html'
print(url)
a=requests.get(url)
a.encoding = a.apparent_encoding #重定义编码为UTF-8
b=re.findall('<h2><a.*</a></h2>',a.text) #通过正则筛选包含标签和中文标题的关键字段
for i in b:
e=e+1
c = re.findall(('[\d]{5}'), i) #通过正则筛选出每个页面的关键标签
#print(c)
c1=re.findall('target="_blank">(.*)</a></h2>',i) #通过正则筛选出标题
url1=f'https://www.1ppt.com/plus/download.php?open=0&aid={c[0]}&cid=3'#把标签带入到网址生成下载页面
#下载
aa=requests.get(url1)
aa.encoding = aa.apparent_encoding
bb=re.findall('https.*zip',aa.text)
res = requests.get(bb[0])
pic = res.content
photo = open(f'C:\下载/{c1[0]}.zip', 'wb') # 把文件名生成到下载名称
photo.write(pic)
photo.close()
print(e,f'{c1[0]} 下载完成')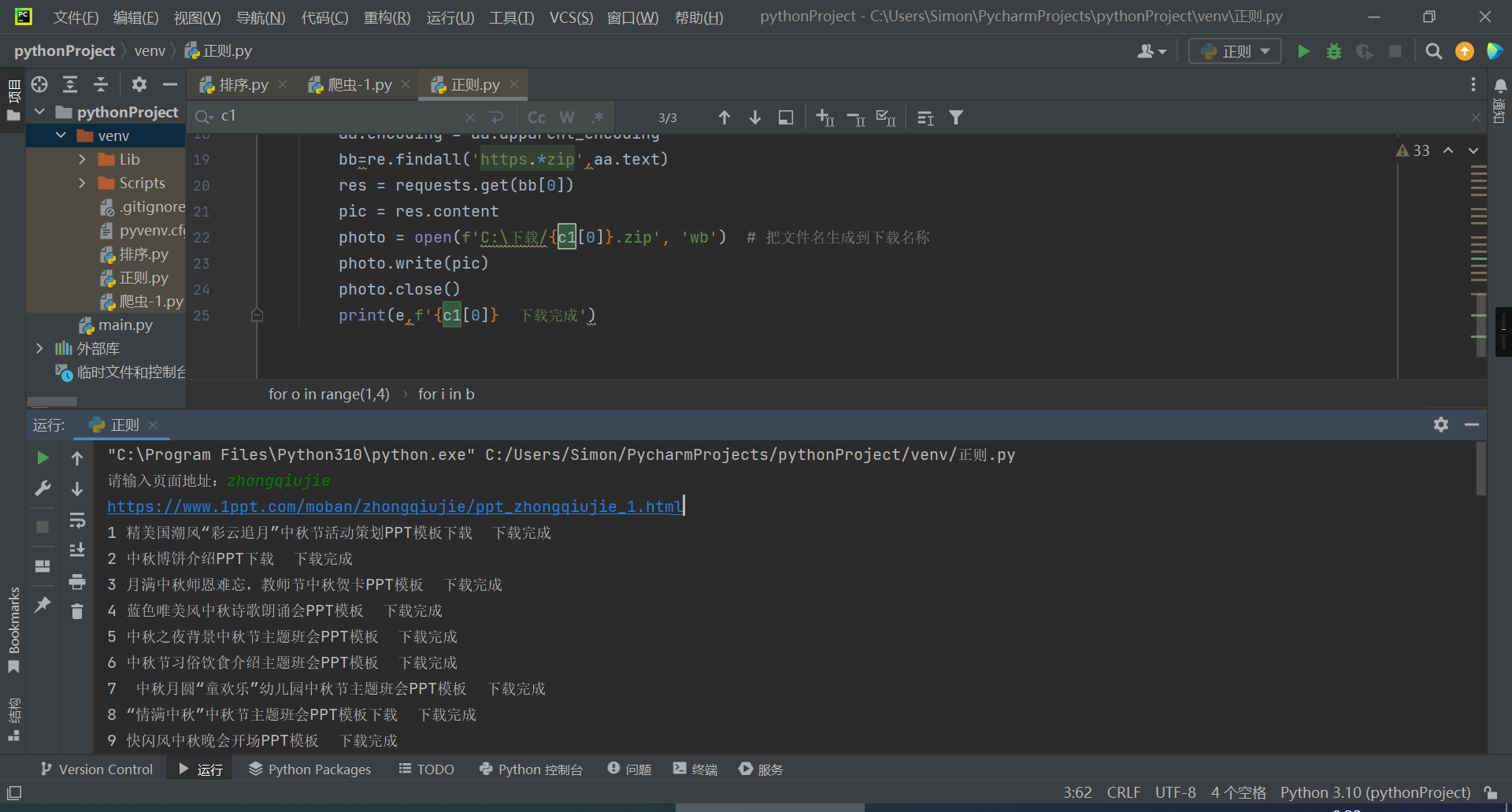
知识点:aa.encoding = aa.apparent_encoding,解决网页编码问题。